How to Choose Hardware for Your Machine Learning Project?




As technological advances allow us to foray into the untapped potential of data analysis, machine learning has emerged as a revolutionizing model that has been embraced worldwide.
From healthcare to the automobile sector to marketing and transportation – machine learning has allowed organizations to discover valuable insights, improve productivity and operate efficiently.
But how does it work, and how should you choose machine learning hardware for your machine learning project?
#What Is Machine Learning?
There is no single definition for machine learning. Nvidia puts it as "the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world." Whereas McKinsey&Company further add that machine learning is "based on algorithms that can learn from data without relying on rules-based programming."
Simply put, machine learning is a branch of artificial intelligence (AI) that focuses on developing applications and systems that can learn and improve without being programmed to do so. For example, in chatbot development, how an AI-powered chatbot learns through past interactions to make more informed judgments in the future. Chatbots with voice capabilities take this a step further by understanding and responding to spoken language, making interactions more seamless and natural for users.
Let's pretend that we have to find out whether a drink is a coffee or tea. We would have to build a system to answer this question based on the collected data.
We use training to build a model for such a question. The goal is to have a system that finds answers to our proposed question as accurately as possible. In the broader context of artificial intelligence and machine learning development, this first step of gathering and preparing quality data is absolutely critical. Even the most advanced algorithms can’t deliver accurate results without a solid foundation of clean, well-structured data.
#Collecting & Gathering Data
The initial step is gathering data required to 'train' our 'model'. In the broader context of artificial intelligence and machine learning development, the first step of gathering and preparing quality data is absolutely critical. Even the most advanced algorithms can’t deliver accurate results without a solid foundation of clean, well-structured data. The quality of the data collected directly impacts the accuracy of your machine learning model, which is why it is crucial to ensure the data has been prepared and manipulated for your chosen model.
In our example, we can utilize cups of tea and coffee as data. We can use many components, but for our purposes, we'll pick two simple ones—the color of the drink and the caffeine quantity.
First, we need to have a variety of tea and coffee ready and get equipment for measurements-- a spectrometer for measuring the color and a UV range spectrophotometer to measure the caffeine content.
Then, we'll use the data collected to establish a table of color, caffeine content, and whether it's tea or coffee. This is going to be the training data.
#Algorithm Selection
Once we've gathered quality data from data annotation and collection, the next step involves choosing the best-fit model.
Many engineers and data scientists find choosing the correct algorithm an uphill task. Despite the abundance of algorithm models available, you have to make sure the selected models align with the data at hand and the project requirements.
In our case, we have just two data points-- color and caffeine percentage. Therefore, we can use a simple linear model, such as the logistic regression algorithm.
The formula for a logistic function is y = 1 / (1 + e^-(β0 + β1x1 + … + βnxn)) and the output is between 0 and 1. We keep adjusting β values until we maximize prediction accuracy and minimize the cost function.
#Feature Engineering
The next step involves transforming data to make it easier to interpret for the model, increasing the accuracy. Visualizing your data is essential to see if you've missed any relationships between different variables or adjust any data imbalances.
Feature engineering allows you to highlight crucial data, allowing the model to focus on the most important criteria. It also enables you to input domain expertise into the model, further elevating the level of accuracy.
#Model Training
At the very core of machine learning is the model training procedure. Going with our example, we'll use our data to incrementally grow our model's ability to predict whether the drink is coffee or tea accurately.
Since we've gone with a linear model, the only variables we can affect or change are the slope and the y-intercept.
In machine learning, the collection of the variables mentioned above are usually formed into a matrix that is denoted w for the weights and b for the biases. Now we initialize random values for w and b and attempt to predict the outputs.
This is a repetitive process that is only perfected through trial and error. Each iteration results in the updating of weights and biases, which is called one training step. As each stage progresses, our model moves step by step closer to the ideal line of separation between coffee and tea.
Once training is finalized, we check to see if our model lives to our expectations.
We evaluate our models performance using the testing dataset. This is to see how the model performs against data that is new. This is a reflection of how well the model might do in practical use.
After establishing a strong framework for our model, we can integrate external tools to bolster its efficacy.
For example, using the ZenRows web scraping API tool could potentially enable the extraction of additional valuable data from various sources.
#Inference
Once we've done all the hard work, we get to the actual point of machine learning: to find answers. Inference is where we get those answers. We run our project and see how well our model accurately predicts whether a drink is a coffee or tea using the given data.
The beauty here is that we could differentiate between coffee and tea with our model as a replacement for human judgment.
And this same process can apply to any question or problem presented in any field or domain, with some degree of change.
However, the performance of a machine learning system is highly dependent on the hardware deployed. A model may be extraordinary, but if the machine learning hardware isn't up to par, the process can become too exhausting.
#Possible Machine Learning Hardware Choices For Machine Learning Project
Machine learning algorithms vary in compute intensity. The most popular algorithms today, like deep neural networks or support vector machines, are very computationally intensive. Training such models requires tons of compute resources.
Choosing the correct machine learning hardware is a complicated process. Let's look at the three core hardware options for machine learning: processing units, memory, and storage.
#Processing Units
Central Processing Unit (CPU)
Given that most machine learning models run on GPU nowadays, CPUs are primarily used for information preprocessing. Their design is accustomed to serial operations, so they support increased cache memory and less cores to complete complicated instructions quickly.
The CPU's strength is executing a few complex operations in sequence as quickly as possible, while machine learning usually involves large quantities of relatively simple linear algebra computations that are best processed in parallel.
However, if you are working on machine learning projects that are not using complex algorithms and don’t need much compute resources, a GPU might not be needed.
For instance, the i7-7500U CPU is an excellent option to consider if your machine learning project is light-weight since it can process 100+ examples per second. The Threadripper 1900x, an eight-core CPU with 16 hyper threads from AMD, is another excellent option if you're willing to go with CPUs.
That said, CPUs cannot compete with GPU since the CPU is often overpowered but understaffed.
Intel Phi attempted to compete with NVIDIA/AMD GPUs, but the former still lacks performance, as seen in the graph below.
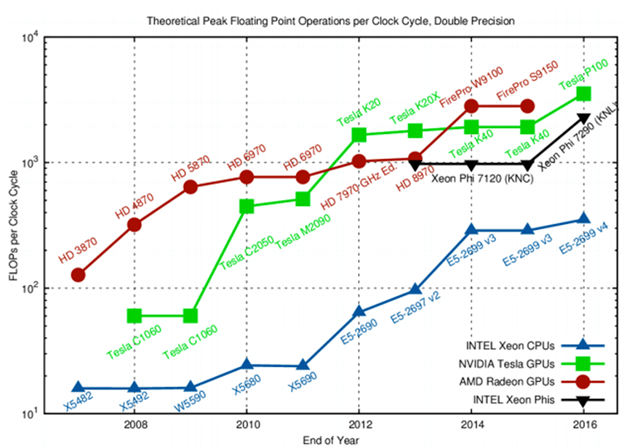
If your tasks are not fit for a CPU to handle, there are great GPU options to look for.
Graphical Processing Unit (GPU)
Compared to conventional CPUs, GPUs consist of thousands smaller cores that allow for extensive parallel computing, and higher throughput - more computations can be done in a given moment.
A GPU was initially created for graphical processing workloads, but was later found to be very useful for general purpose computing in science, product design and other fields. Machine learning data is typically stored as matrixes with matrix-matrix multiplication being the most common procedure. GPU computing is great for such computations and can speed them up to 7 times.
Speaking about memory, it’s important to consider the size of your machine learning model, and whether it fits in the VRAM memory of your GPU. For instance, 10GB of VRAM memory should be enough for businesses doing deep learning prototyping and model training.
Modern GPU cards, like the RTX series, support 16-bit VRAM memory that helps you squeeze out nearly twice as much performance for the same amount of memory, when compared with the older 32-bit architecture.
NVIDIA GPUs are usually an excellent option for machine learning. The CUDNN and CUDA programming interfaces are exceptionally viable with the current machine learning libraries such as Keras, Tensorflow, or PyTorch.
The following two models are excellent choices, as they offer outstanding performance, which we suggest you take a look at when choosing a GPU for your machine learning project.
- Nvidia RTX 3080 (8704 CUDA cores, 10GB GDDR6 memory)
- Nvidia RTX 3070 (5888 CUDA cores, 8GB GDDR6 memory)
The RTX 3080 Ti is 20 to 50% faster than the RTX 3070, though it is more expensive as well. Though these models are probably the most popular today, there are also many other options for machine learning GPUs available.
If budget is a concern, you can cut down on your expense by purchasing a bit less expensive GPU and simply running your computations longer. Models such as a GTX 1080 or GTX 1070 are excellent cost-effective alternatives.
Field-programmable Gate Array (FPGA)
Known for their power efficiency, FPGAs deliver flexible architectures to programmable hardware resources as well as to DPS and BRAM blocks. This allows reconfiguring the data path at run time through partial reconfiguration. Due to this, the user has no restrictions and can go along with parallel computations.
Additionally, FPGAs offer unparalleled flexibility when compared to CPUs and GPUs. It enables them to have any-to-any I/O connection, allowing users to connect with any device or network without requiring a CPU.
FPGAs are used in areas where functional safety has an essential role. Therefore, FPGAs are designed to meet the safety requirements of a variety of different applications.
Xilinx Zynq-7000, along with Ultrascale+TM MPSoC, are examples that support safety-critical apps.
Application-specific Integrated Circuit (ASIC)
ASIC, as the name implies, are circuits designed for a specific use. These are specialized devices built to complete predefined computations with enhanced efficiency.
In contrast, CPUs can be used for general purposes. Even GPUs consist of parallel processors where they can perform several different algorithms at once. Unlike the FPGA, ASICs are non-programmable once made. While you may reprogram an FPGA once it has accomplished its objective, ASICs logic is permanent.
However, ASICs' key advantage is their efficiency as they are designed to complete a predefined task only. This also leads to increased efficiency.
Take AlphaGo, for example. When the primary AlphaGo versions were executed on TPUs, they consumed less energy than when they were run on CPU and GPU clusters.
All tech giants are interested in developing and investing in ASICs. Currently, Google has introduced the Tensor Processing Unit's third iteration, an ASIC established for training as well as inference.
#Memory
With machine learning capabilities experiencing an exponential increase, AI applications require enhanced memory features that can handle the increasing workloads while maintaining efficiency. The three primary types of memory to consider for machine learning applications are:
- On-chip memory
- HBM (high bandwidth memory)
- GDDR memory
On-chip memory is the fastest memory type that is at the top of the memory hierarchy. It is situated close to the compute cores of your CPU and GPU, which makes on-chip memory really quick, but also limits its capacity. It serves as a local cache memory for microprocessors to store recently accessed information.
HBM is a 3-D stacked memory option built on the DRAM architecture. Designed to enhance performance, it allows you to leverage increased bandwidth and capacity. While not as efficient as on-chip memory, it still ensures an efficient operation by maintaining low data rates.
The latest HBM version, the HBME2, is a noteworthy mention of a memory option that is fit for various machine learning applications.
Lastly, the GDDR memory can originally be traced back to gaming applications, but people recognized their efficacy in machine learning programs. The current GDDR6 can support high data rates that reach 16 gigabytes per second.
#Storage
Storage usually is not a source of concern for machine learning and usually comes down to budget. Having any hard drive or SSD larger than 3 TB for data would be sufficient.
If your pocket allows, a 500 GB NVMe M2 SSD is a good option.
Storage doesn't matter during training since your data will be residing in RAM or GPU VRAM, though it is still better to have an SSD than HDD as the performance is worth the price.
#How Hardware Can Help Accelerate Machine Learning Workloads
Workload is the volume of processing that a computer has to complete at a given time. Quality hardware is needed everywhere in the pipeline, whether you adapt existing architectures or develop new ones.
#What Improvements Can We Expect?
The improvements suitable hardware bring are many, but identifying the most important ones would be the following:
- Lower latency inference,
- Higher throughput training, and
- Lower power consumption, leading to lower power costs.
Thousands of machine learning hardware products are available in the market, but it is essential to understand which ones are worth the upgrade and how they impact your performance.
At Cherry Servers, we offer AI server infrastructure solutions that scale with your needs. You can add a suitable Nvidia GPU accelerator to a custom dedicated bare metal cloud server and configure it to the requirements of your ML or deep learning application.




