A Complete Introduction to GPU Programming With Practical Examples in CUDA and Python




#What is GPU Programming?
GPU Programming is a method of running highly parallel general-purpose computations on GPU accelerators.
While the past GPUs were designed exclusively for computer graphics, today they are being used extensively for general-purpose computing (GPGPU computing) as well. In addition to graphical rendering, GPU-driven parallel computing is used for scientific modelling, machine learning, and other parallelization-prone jobs today.
#CPU vs. GPU Computing Differences
A Central Processing Unit (CPU) is a latency-optimized general-purpose processor that is designed to handle a wide range of distinct tasks sequentially, while a Graphics Processing Unit (GPU) is a throughput-optimized specialized processor designed for high-end parallel computing.
The question of whether you need a GPU accelerator boils down to the specifics of the problem you are trying to solve. Both CPU and GPU have different areas of excellence and knowing their limitations will leave you better off when trying to decide whether to use GPU programming for your project.
Deploy and scale your Python projects effortlessly on Cherry Servers' robust and cost-effective dedicated or virtual servers. Benefit from an open cloud ecosystem with seamless API & integrations and a Python library.
#GPU Programming APIs
GPU understands computational problems in terms of graphical primitives. Today there are several programming frameworks available that operate these primitives for you under the hood, so you could focus on the higher-level computing concepts.
#CUDA
Compute Unified Device Architecture (CUDA) is a parallel computing platform and application programming interface (API) created by Nvidia in 2006, that gives direct access to the GPU’s virtual instruction set for the execution of compute kernels.
Kernels are functions that run on a GPU. When we launch a kernel, it is executed as a set of Threads. Each thread is mapped to a single CUDA core on a GPU and performs the same operation on a subset of data. According to Flynn‘s taxonomy, it‘s a Single Instruction Multiple Data (SIMD) computation.
Threads are grouped into Blocks and when a kernel is launched, they are mapped to a corresponding set of CUDA cores. Blocks are further grouped into Grids, and each kernel launch creates a single grid.
CUDA programming model allows software engineers to use a CUDA-enabled GPUs for general purpose processing in C/C++ and Fortran, with third party wrappers also available for Python, Java, R, and several other programming languages. CUDA is compatible with all Nvidia GPUs from the G8x series onwards, as well as most standard operating systems.
#OpenCL
While CUDA is a proprietary framework, OpenCL is an open standard for parallel programming across heterogeneous platforms created by the Khronos Group. OpenCL works with central processing units (CPU), graphics processing units (GPU), digital signal processors, field-programmable gate arrays (FPGA) and other processors or hardware accelerators.
OpenCL is extremely versatile and has been successfully adopted by tech industry giants, including AMD, Apple, IBM, Intel, Nvidia, Qualcomm, Samsung, and many others. It is based on C/C++ language, with third-party wrappers also available for Python, Java, R, GO, JavaScript, and many others.
#OpenACC
OpenACC is a user-driven directive-based parallel programming standard designed for scientists and engineers interested in porting their codes to a wide variety of heterogeneous high-performance computing (HPC) hardware platforms. The standard is designed for the users by the users.
OpenACC aims to simplify parallel programming of heterogeneous CPU/GPU hardware platforms and architectures with significantly less programming effort than required with a low-level model. It supports C/C++ and Fortran programming languages.
#GPU Programming with CUDA and Python
There are several standards and numerous programming languages to start building GPU-accelerated programs, but we have chosen CUDA and Python to illustrate our example. CUDA is the easiest framework to start with, and Python is extremely popular within the science, engineering, data analytics and [deep learning](deep learning) fields – all of which rely heavily on parallel computing.
Even in Python you may approach GPU programming at different layers of abstraction. It is reasonable to start at the highest layer of abstraction that satisfies your application, if you don’t need additional customization and control capabilities that lower layers of abstraction can provide.
Let’s review the ways of using CUDA in Python starting with the highest abstraction level and going all the way down to the lowest.
#CUDA for Specialized Libraries
If you only want to work with neural networks or any other deep learning algorithm, specialized deep learning libraries like Tensorflow or PyTorch are probably the right choice for you. These libraries can automagically switch between CPU and GPU processing under the hood for you.
#CUDA as Drop-in Replacement
In case you are a scientist working with NumPy and SciPy, the easiest way to optimize your code for GPU computing is to use CuPy. It mimics most of the NumPy functions and allows you to simply drop-in and replace your NumPy code with CuPy functions that are processed on a GPU instead of a CPU. CUDA For Custom Algorithms
When you need to use custom algorithms, you inevitably need to travel further down the abstraction hierarchy and use NUMBA. It has bindings to CUDA and allows you to write your own CUDA kernels in Python. This way you can very closely approximate CUDA C/C++ using only Python without the need to allocate memory yourself.
#CUDA as C/C++ Extension
If you want the highest level of control over the hardware like manual memory allocation, dynamic parallelism, or texture memory management there is no way around using C/C++. The most convenient way to do so for a Python application is to use a PyCUDA extension that allows you to write CUDA C/C++ code in Python strings.
#How to Get Started with CUDA for Python on Ubuntu 20.04?
#Install CUDA on Ubuntu 20.04
First off you need to download CUDA drivers and install it on a machine with a CUDA-capable GPU. In order to install CUDA on Ubuntu 20.04 using a local installer, follow these instructions:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.4.2/local_installers/cuda-repo-ubuntu2004-11-4-local_11.4.2-470.57.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-4-local_11.2-470.57.02-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-4-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
#Install CuPy Library
Next off, we need to install a Python library to work with CUDA. As discussed above, there are many ways to use CUDA in Python at a different abstraction level. As NumPy is the backbone library of Python Data Science ecosystem, we will choose to accelerate it for this presentation.
The easiest way to NumPy is to use a drop-in replacement library named CuPy that replicates NumPy functions on a GPU. You can install the stable release version of the CuPy source package via pip:
pip install cupy
#Write a Script to Compare CPU vs. GPU
Finally, you want to make sure that CuPy works fine on your system and how much can it enhance your performance. To do so, let’s write a simple script that would do the trick.
Let’s import NumPy and CuPy libraries, as well as time library that we are going to use to benchmark processing units.
import numpy as np
import cupy as cp
from time import time
Next, let’s define a function that is going to be used for benchmarking.
def benchmark_processor(arr, func, argument):
start_time = time()
func(arr, argument) # your argument will be broadcasted into a matrix automatically
finish_time = time()
elapsed_time = finish_time – start_time
return elapsed_time
Then you need to instantiate two matrices: one for CPU and one for GPU. We are going to choose a shape of 9999 by 9999 for our matrices.
# load a matrix to global memory
array_cpu = np.random.randint(0, 255, size=(9999, 9999))
# load the same matrix to GPU memory
array_gpu = cp.asarray(array_cpu)
Finally, we want to run a simple addition function to determine the performance difference on CPU vs. GPU processor.
# benchmark matrix addition on CPU by using a NumPy addition function
cpu_time = benchmark_processor(array_cpu, np.add, 999)
# you need to run a pilot iteration on a GPU first to compile and cache the function kernel on a GPU
benchmark_processor(array_gpu, cp.add, 1)
# benchmark matrix addition on GPU by using CuPy addition function
gpu_time = benchmark_processor(array_gpu, cp.add, 999)
# determine how much is GPU faster
faster_processor = (gpu_time - cpu_time) / gpu_time * 100
And print the result out to the console.
print(f"CPU time: {cpu_time} seconds\nGPU time: {gpu_time} seconds.\nGPU was {faster_processor} percent faster")
After running this script on an Intel Xeon 1240v3 machine with Nvidia Geforce GT1030 GPU accelerator from Cherry Servers GPU Cloud, we’ve confirmed that integer addition runs many times faster on a GPU. For instance, GPU runs integer addition ~1294 times faster when 10000x10000 matrix is being used.
In fact, the bigger the matrix, the higher performance increase you may expect.
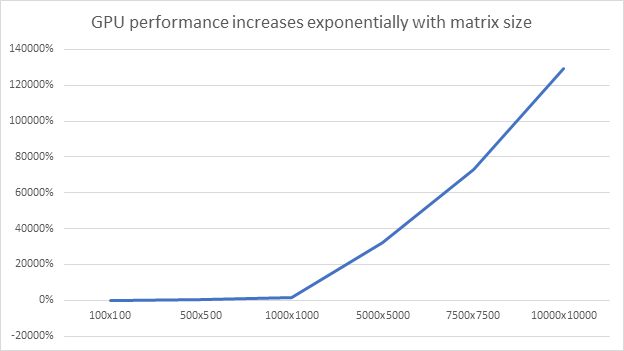
Image 1 – GPU performance increase.
We’ve compared CPU vs GPU performance (in seconds) by using integer addition for 100x100, 500x500, 1000x1000, 7500x7500 and 10000x10000 two-dimensional matrices. The GPU starts to significantly outpace CPU when large enough matrices are used.
#To Wrap up
If you are working with large chunks of data that can be processed in parallel, it’s probably worth to dive deeper into GPU programming. As you have seen, the performance increase is significant when using GPU computing for processing large matrices. By the end of a day, it may save you precious time and resources, if your application can utilize parallel computing.






