How to Restart a Pod in Kubernetes? Methods and Best Practices




Pods are essential for deploying and scaling applications in Kubernetes. When a Pod starts having issues such as high resource consumption or misconfigurations, updating and restarting the Pod may be the solution. Restarting a Pod fixes many issues and enables you to add new Pod configuration changes.
In this article, you will learn when it is important to restart a Pod and how to restart the Pod in order to fix issues and optimize the cluster.
#Prerequisites
You need a running Kubernetes cluster and have at least basic knowledge on how to create a Pod you will use in this tutorial.
Build and scale your self-managed Kubernetes clusters effortlessly with powerful Dedicated Servers — ideal for containerized workloads.
#Why should you restart a Kubernetes Pod?
Restarting a Pod is a remedy for many issues that Pods face. However, not every error or problem a Pod experiences can be solved with a restart. Below are the valid reasons for restarting a Pod.
-
Fixing resource issues: Pods can experience resource-related issues such as CPU throttling and memory leaks. If a Pod uses all the resources it was allocated to within a short time, the containers and applications hosted by the Pod will be starved of resources. Uncontrolled resource issues degrade application performance or can even crash the application. Restarting the Pod minimizes the resource issue by resetting CPU usage and clears temporary memory issues.
-
Updating Pod configuration: When you make Pod configuration changes such as updating the Pod’s environment variables or updating the Secret and ConfigMaps, it is important to restart the Pod so that the changes can be applied.
-
Debugging and troubleshooting Pods: Restarting a misbehaving Pod can help clear temporary issues or glitches. Also, restarting a Pod can trigger the generation of diagnostic logs or metrics that are useful for troubleshooting. Monitoring the Pod during and after the restart can provide insights into the root cause of issues.
The status of the Pod determines whether the Pod needs a Restart or not. A Pod that is consistently failing and in a pending status needs a troubleshooting procedure. A Pod goes through 5 stages in its lifecycle. Below are the 5 stages of the Pod lifecycle:
-
Pending: A Pod gets in the pending phase when it is being scheduled and bound to a node and necessary resources. The Pod has been created but isn't yet running on a node. It is called the pending phase because the Kubernetes scheduler is still looking for a node that will run the Pod.
-
Running: After a Pod has been assigned to a node it moves to the running phase where it will start to execute its tasks such as starting networks. This is the stage where the Pod starts pulling the container’s image from the registry and setting up storage volumes and networks. Also, Kubernetes prepares the environment for the containers. This is the functional stage of the Pod. Kubernetes will monitor the resource usage and the health of the Pod using readiness and liveness probes.
-
Success or Failure: The success and failure of the Pod is determined by the status of the containers. If containers fail because of persistent errors the Pod will fail too. If the containers execute their tasks successfully the Pod will be successful.
-
Termination: If a node running the Pod fails, the Pod will automatically get terminated. Deployment scalability and API server issues can also lead to a Pod being terminated. The Pod’s resources will be released after it gets terminated. A Pod can also get into a phase called “Unknown” if the Kubernetes control plane cannot determine the status of the Pod.
#Different methods for restarting a Kubernetes Pod
In this section, you will learn various ways that can be used to restart a Pod. Every method has its own pros and cons. Below are different techniques you can implement to restart Pods.
#Restarting a Pod by Scaling the number of Pods
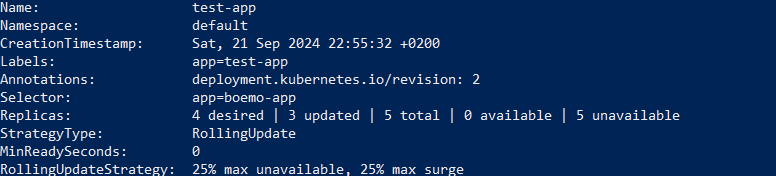
When traffic increases or decreases it is important to scale the deployments to make sure that resources are used efficiently and no downtime occurs. Whenever you scale the number of Pods, Kubernetes will automatically restart the Pods whether you are scaling up or down. Use the following command to increase or decrease the number of Pod replicas.
kubectl scale deployment <deployment name> -n <namespace> --replicas=3
You will get the following output that shows the number of new replicas created.
#Restarting a Pod by updating configuration specifications
When you change the Pod’s configuration, Kubernetes will be forced to restart the Pod in order to apply and enable the new changes added to the Pod’s configuration file. Updating the Pod configuration with new variables and values that are incorrect will cause more errors. This method of restarting the Pod by updating its specifications is complex. So, it is important to ensure that the configuration updates are made accurate.
Use the following command to restart a Pod by replacing its configuration with new configuration details using a YAML file.
kubectl get pod <pod_name> -n <namespace> -o yaml | kubectl replace --force -f -
#Restarting a Pod by Deleting it
One of the most straightforward ways to restart a Pod is by deleting it. Kubernetes controllers like Deployments and ReplicaSets ensure that the desired number of Pods are running. When you delete a Pod that's managed by a controller, Kubernetes automatically creates a new one to replace it using the specified configuration. Use the following command to delete a Pod.
kubectl delete pod <pod_name> -n <namespace>
#Using the rollout restart command
The kubectl rollout restart command allows you to restart Pods for a specific deployment gradually without experiencing downtime. Use the following command to restart a deployment rollout.
kubectl rollout restart deployment <deployment_name> -n <namespace>
Also read: How to deploy Kubernetes on Bare Metal
#Best practices for restarting Kubernetes Pods
Abruptly restarting Pods can have serious consequences on the containers. That is why it is important to follow best practices when restarting Pods. This section will teach you different ways you should follow in order to safely restart Pods.
-
Use liveness and readiness probes: The liveness probe is used to check if an application in a Pod is failing or crashing. The status of the application is used to determine the health of the Pod. The liveness probe is crucial because it can be instructed to restart the application if it crashes after a certain specified period of time. On the other hand, the readiness probe is used to check if an application is ready to start receiving incoming traffic. Before you start sending traffic to the newly deployed application it is important to use the readiness probe to know when an application is ready to start receiving incoming traffic. Doing this will help save resources and prevent traffic from being sent to unhealthy and unready applications.
-
Monitor Pod restarts: After restarting the Pod plans might not go well as expected. So, it is important to monitor the restarted Pods to ensure that you are alert when they fail. You can monitor them by analyzing logs or setting up metrics collection tools such as Prometheus to collect metrics and notify you when the Pod exceeds set thresholds.
-
Avoid frequent restarts: Frequent Pod restarts can lead to instability and performance degradation. It's important to minimize unnecessary restarts to maintain a healthy Kubernetes environment.
-
Test in non-production environment: Before restarting Pods that are in the production environment it is important to test the new changes in the development environment. Testing a Pod helps you to identify issues early and validate changes before deploying the new version to the live environment.
#Conclusion
In this guide, you have learned various reasons why it is necessary to restart a Kubernetes Pod and how to restart the Pod in different ways. In addition, you have learned best practices to follow when restarting Pods.
Consistently experiencing the need to restart Pods might be a sign of a bigger underlying problem. Restarting a Pod solves surface problems. Persistent resource and network issues need full troubleshooting and solutions. Deeper resource issues can be solved by expanding memory and CPU. Fortunately, Cherry Servers offers elastic cloud storage solutions that include security such as RBAC. Fix your Kubernetes resource issues by using a premium storage bandwidth at a lower cost.




